
Track 1: Multi-Camera 3D Perception
Challenge Track 1 involves synthetic animated people data in multiple indoor settings generated using the Isaacsim.Replicator.Agent (IRA) and Isaacsim.Replicator.Object (IRO) extensions in the NVIDIA Omniverse platform.
the NVIDIA Omniverse Platform. The 2025 edition expands last year’s corpus with:
| Split | Hours | Cameras | Scenes | Resolution / FPS | Objects in Training GT* | File Size |
| Train + Val | ≈42 h | 504 | 19 indoor layouts (warehouse, hospital, retail, office) | 1080 p @ 30 fps | 363 instances (292 person + service robots / forklifts) | 74 GB ( depth maps optional, >3 TB) |
* Counts refer to the training + validation ground-truth only; the test split is hidden before the release of evaluation system.
Each scene provides temporally-synchronized RGB video, camera calibration, a top-down map, and per-frame 2D/3D annotations. Depth maps (PNG-in-HDF5) are included but very large; feel free to ignore them if storage or I/O is a concern.
- Task
Teams should detect every object and keep the same identity ID while they move within and across all cameras in a scene.
- Submission Format
For compatibility with the official evaluation server, results must be a single plain-text file (track1.txt) where each line describes one detection:
〈scene_id〉 〈class_id〉 〈object_id〉 〈frame_id〉 〈x〉 〈y〉 〈z〉 〈width〉 〈length〉 〈height〉 〈yaw〉
| Field | Type | Description |
| scene_id | int | Unique identifier for each multi-camera sequence. |
| class_id | int | Starting from zero, denoting an object’s category. (Person→0, Forklift→1, NovaCarter→2, Transporter→3, FourierGR1T2→4, AgilityDigit→5.) |
| object_id | int | Positive, unique ID per scene & class. Remains constant across all cameras within the same scene and class. |
| frame_id | int | Zero-based frame index within that scene. |
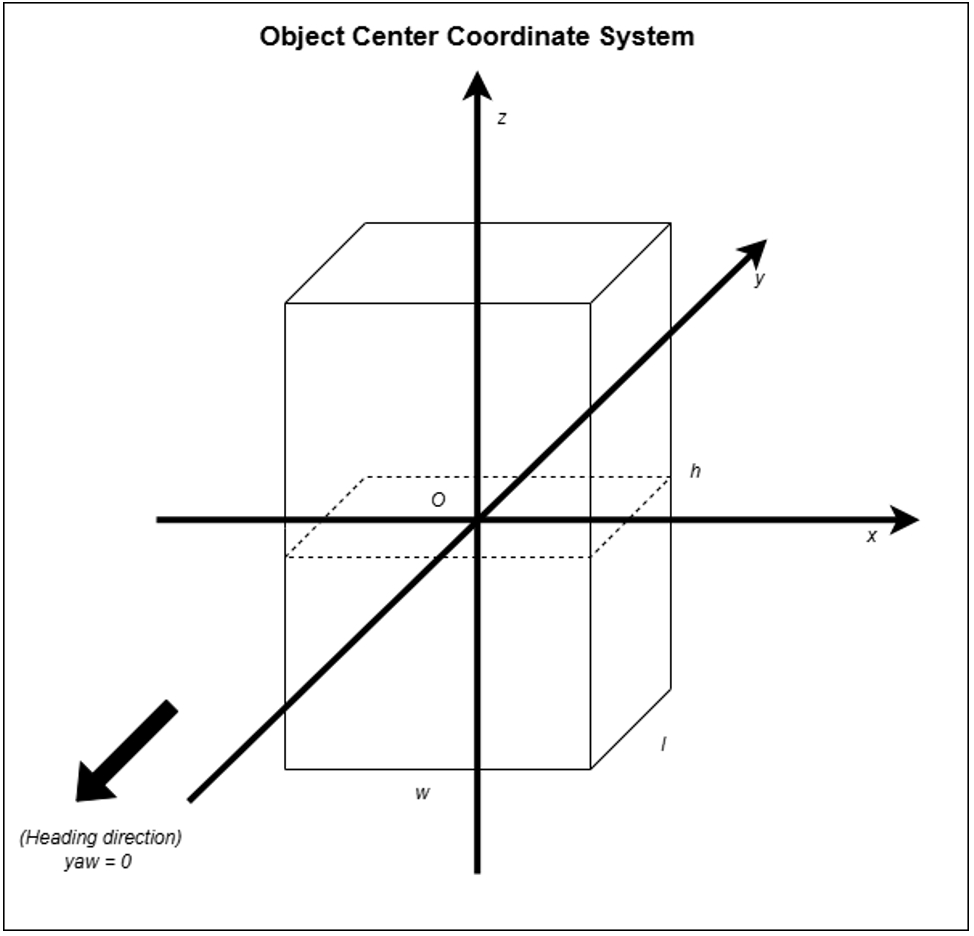
| x, y, z, | float | 3D coordinates of the bounding-box centroid in the world coordinate system which is in meters. |
| width, length, height | float | Box dimensions in meters along its x (width), y (length) and z (height) axes of the object-centered coordinate system, with the origin at the centroid. |
| yaw | float | Euler angle in radians about the y-axis of the object-centered coordinate system defining the box’s heading in the world coordinate system. (Pitch and roll are assumed zero.) |
Example: in scene 0, if a Person is assigned obj_id = 5, then a Forklift cannot use obj_id = 5 (it must use a different ID, e.g. 6).
Archive the text file as track1.zip or track1.tar.gz before uploading.
Important note on the submission file:
- All floating-point numbers in the submission file must be rounded to two decimal places.
- The file size limit for each submission is 50 MB.
- Evaluation
Scores are computed with 3D HOTA [1], which jointly balances detection, association and localization quality. HOTA score will be computed per class within a scene which will be averaged. A weighted average will then be computed on these scores across all scenes based on the total no. of objects. 3D IoU will be used for matching GT & prediction objects.
- Leaderboard = raw HOTA on the hidden test set.
- Online-tracker bonus: If your paper + code prove that only past frames are used, a +10 % multiplicative bonus is applied when deciding the final winner and runner-up (the public leaderboard itself shows the un-bonused score).
Example: Team A (offline) = 66 % HOTA; Team B (online) = 61 % ⇒ bonus → 67.1 % HOTA. Team B ranks higher in the final award list.
- Data Access
Note: Depth files are huge (> 3 TB). If bandwidth or disk is limited, download only the other files.
By downloading you agree to the Physical AI Smart Spaces licence (CC-BY 4.0).
References
[1] J. Luiten et al., “HOTA: A Higher Order Metric for Evaluating Multi-Object Tracking,” IJCV, 2021.